

Make it resilient: Disaster Recovery Techniques
Make it resilient: Disaster Recovery Techniques
Find out what kind of disaster recovery techniques AWS suggest. Which one costs more? And which one helps you recover faster?

Things go wrong from time to time, and you have to be ready to recover from it.
But how do you recover when things break big, and your Cloud provider has issues in Region or Availability Zone? Your manager calls you and says the app is down because AWS has issues in us-easy zone? What do you do?
Well, you need to have proper disaster recovery, which helps you fix things after the shits hit the fan.
There are 4 techniques:
Backup & Restore
Pilot Light
Warm StandBy
Multi-Site Active/Active
And all of them optimize for two things RPO and RTO. So you might be asking what these short words are.
RPO - Recovery point objective
RTO - Recovery time objective
And this probably doesn’t give you too much information. So let’s visualize it.
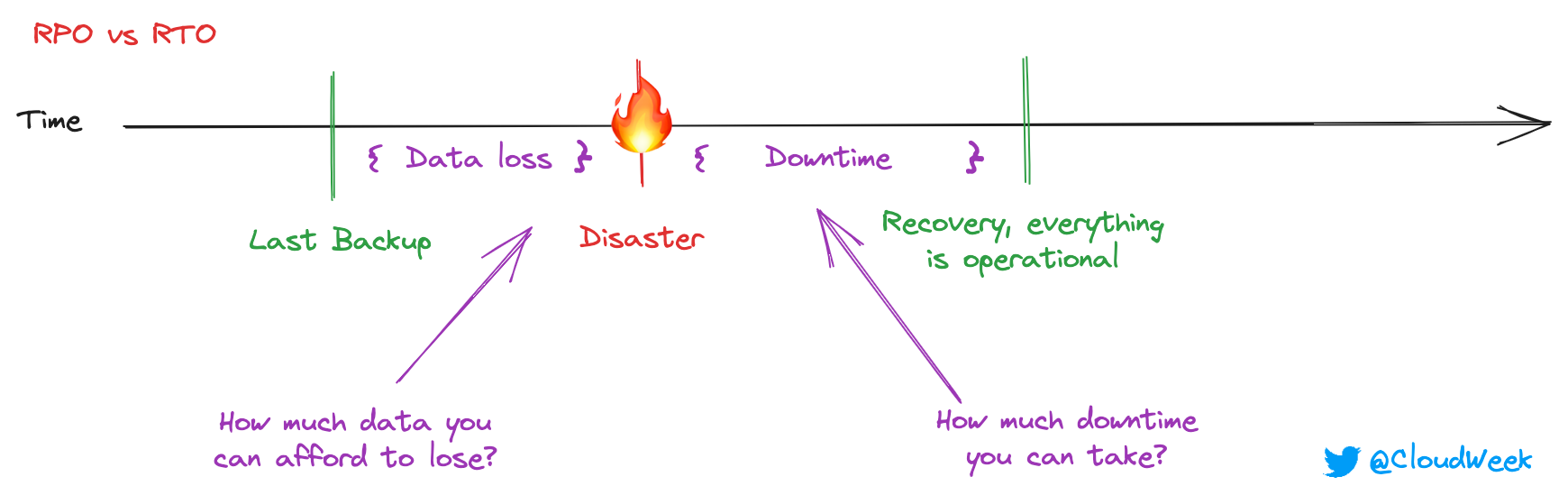
So image should help you understand how we define them and what kind of questions to ask stakeholders:
RPO - How much data you can afford to lose? This will drive your decision on which technique to choose. Different techniques have different RPO, and for critical components, you want to have a low RPO.
RTO - How much downtime you can afford? Again, for critical components where downtime will cost you a ton of money, you want to go with a technique that will lower it. Although, the lower the RTO, the higher the cost of your infrastructure, and you might need to defend it with stakeholders.
Now that we understand these two concepts, we can speak about techniques.
All of the four techniques we mentioned earlier are used to optimize for RPO/RTO.
Backup and Restore
This is the simplest technique, and a lot of people are using it as the default one. If you don’t have backups, at some point you will regret not having it, couple of years ago even Gitlab removed the production database.
On AWS it can be done by performing periodic backups of your databases and media files. RDS supports database snapshots, so that way you can make sure that DB backup exists.
But when disaster happens, your data loss can be in hours, and the time to recover can also be in hours. If you have the entire infrastructure as a code, you can quickly spin up it in a separate region and route traffic to it. But it will take time to load all data from backups.
Backup is done in a way, that once a disaster happens, you would manually spin up everything in a separate Availability Zone or Region and route traffic to that AZ / Region. Nothing is provisioned upfront and because of that, it takes time to recover.

It’s a good technique for noncritical components or if your app still has a small user base. I would argue that you don’t need more advanced techniques if you are a small startup since costs for this one are low and you are still validating your idea.
This can be used for internal applications since they can have higher downtime usually.
Pilot Light
Here things are starting to become more complex since backups are done with DB replicas.
With this technique, you can still store backups in S3, but you need to provision 2 databases in two different Availability Zones. Why? Because these two databases will communicate, and data will be constantly replicated between them.
Because of that, data loss is smaller, but you still don’t have any servers in the second Region / Availability Zone. And until you provision new resources, you can’t serve any traffic.
RPO/RTO is in 10s of minutes because of that. It takes time to spin up infrastructure that will handle all of your traffic.
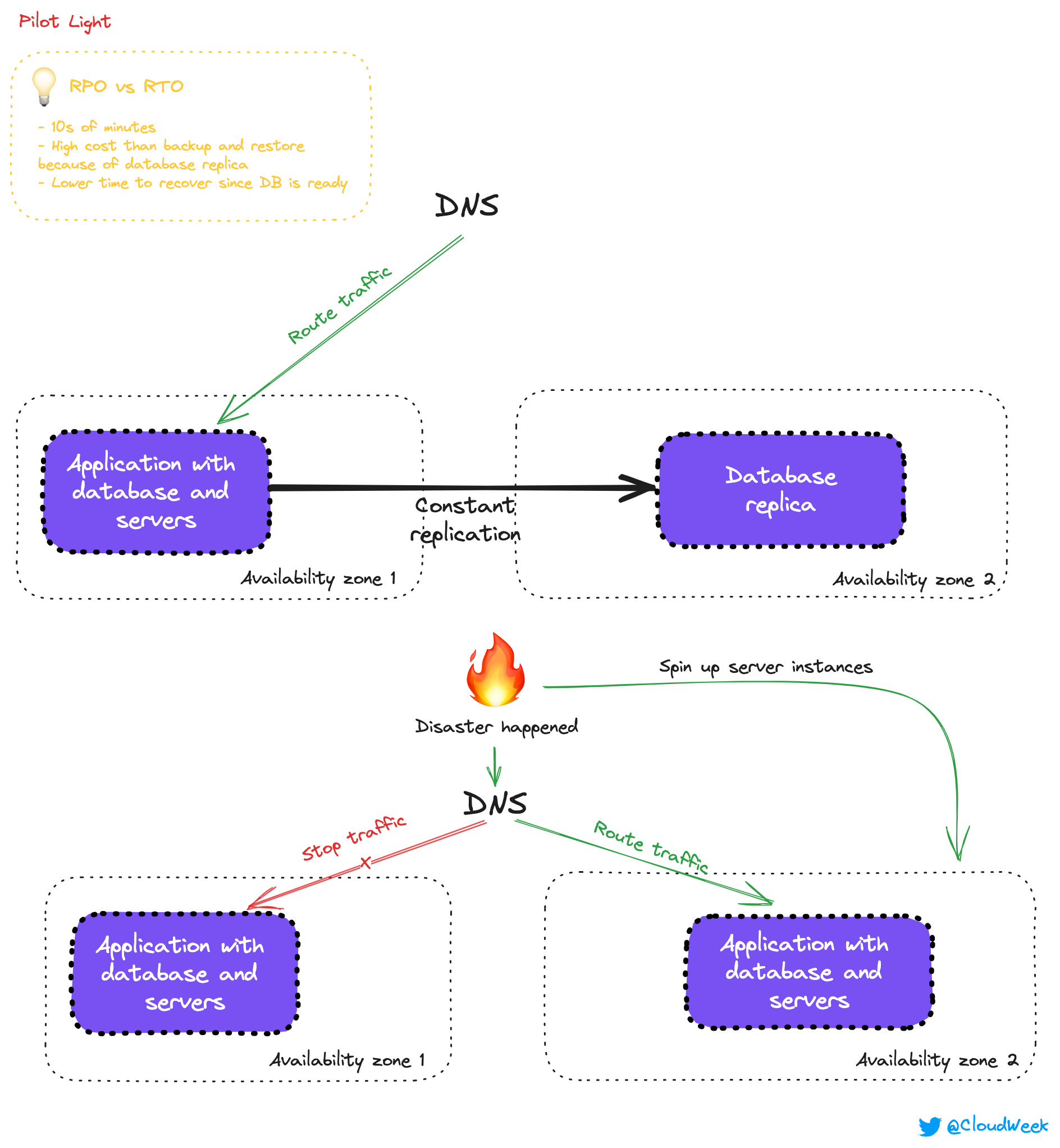
You can see that the costs of this solution are for sure higher because of DB replication. I think it’s still affordable because it helps you recover from failure faster.
DB Replication can be done on AWS with RDS instances since they support Multi-AZ Replication. Multi-region replication is possible only with Aurora instances.
Warm Standby
As the name might suggest to you, it’s a technique with standby instances. Now we are getting to the much lower RTO, and costs start to go up.
With this technique, you have duplicate resources again, but here is what you will have:
DB Replica which is still in constant sync with the primary instance. You probably need to choose wisely what is the size of this instance. If you go for the lower instance, it will take up time to scale after a disaster. But keeping exact replicas will add costs.
Smaller server replicas which can handle traffic immediately after the disaster. They are usually not big enough to handle full traffic because you keep a smaller environment. But since you already have some resources, it will take less time to scale up from here.
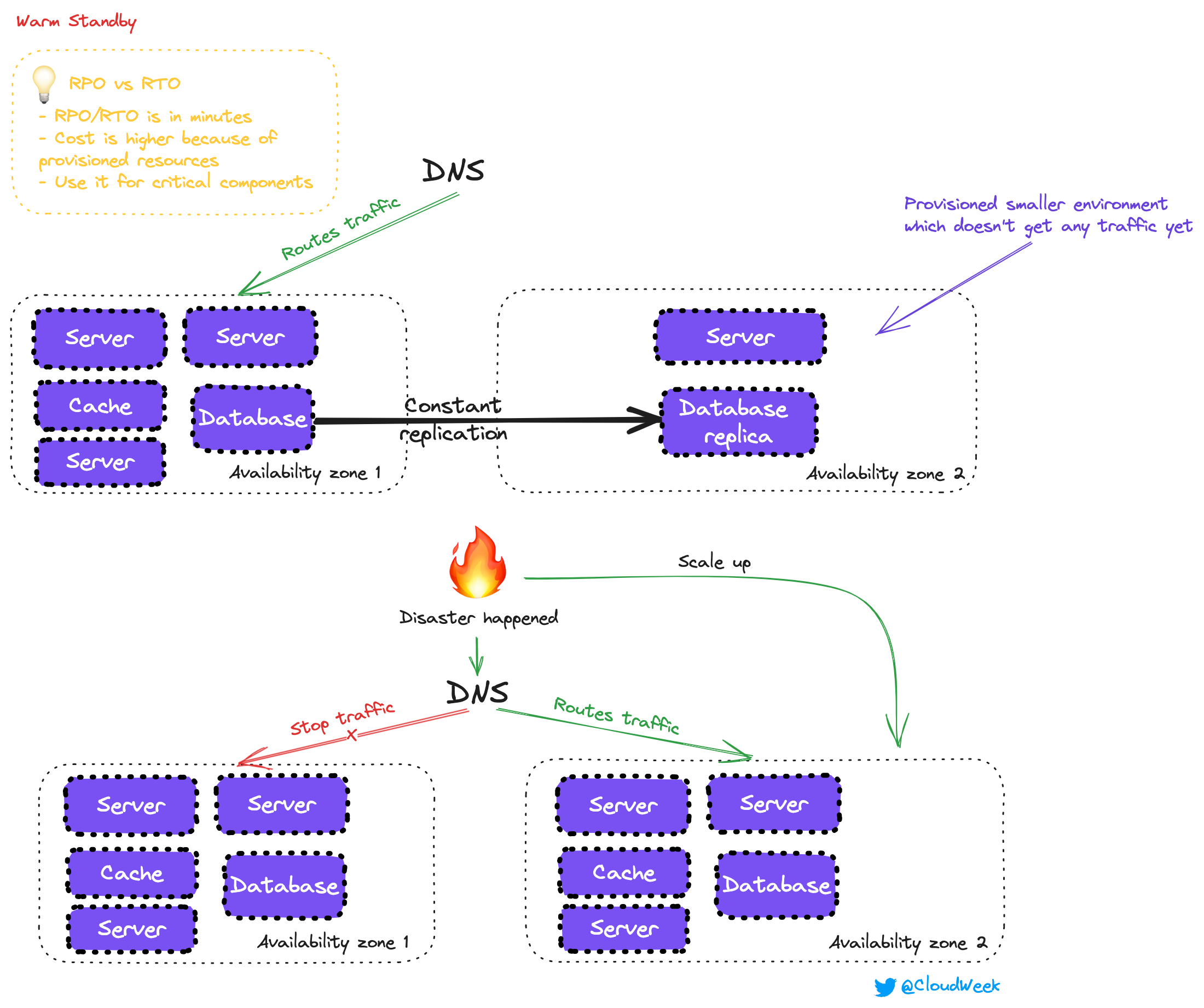
As you can see in the image above, we didn’t provision all resources. Our second instance has only one server, but as disaster happened, scale-up kicked in, and DNS switched traffic to a different zone.
This way, we can recover much faster, in a mater of minutes, but costs will be higher since you need to provision resources that you need for your app to work. If you have multiple things, for example, Open Search, well you need to provision it, it just has to be smaller.
This is mostly good enough for most of the applications unless you are handling a huge amount of traffic and you need to recover in a matter of seconds or you will lose a huge amount of money.
Multi-Site Active/Active
This is an area of zero downtime with disaster recovery. How? You have the app deployed into multiple zones/Regions and route traffic to both of them in parallel.
The cost of this solution is pretty high because everything is replicated in both Zones/Regions. But you won’t have any downtime since if one region goes down, the second one still can serve traffic.
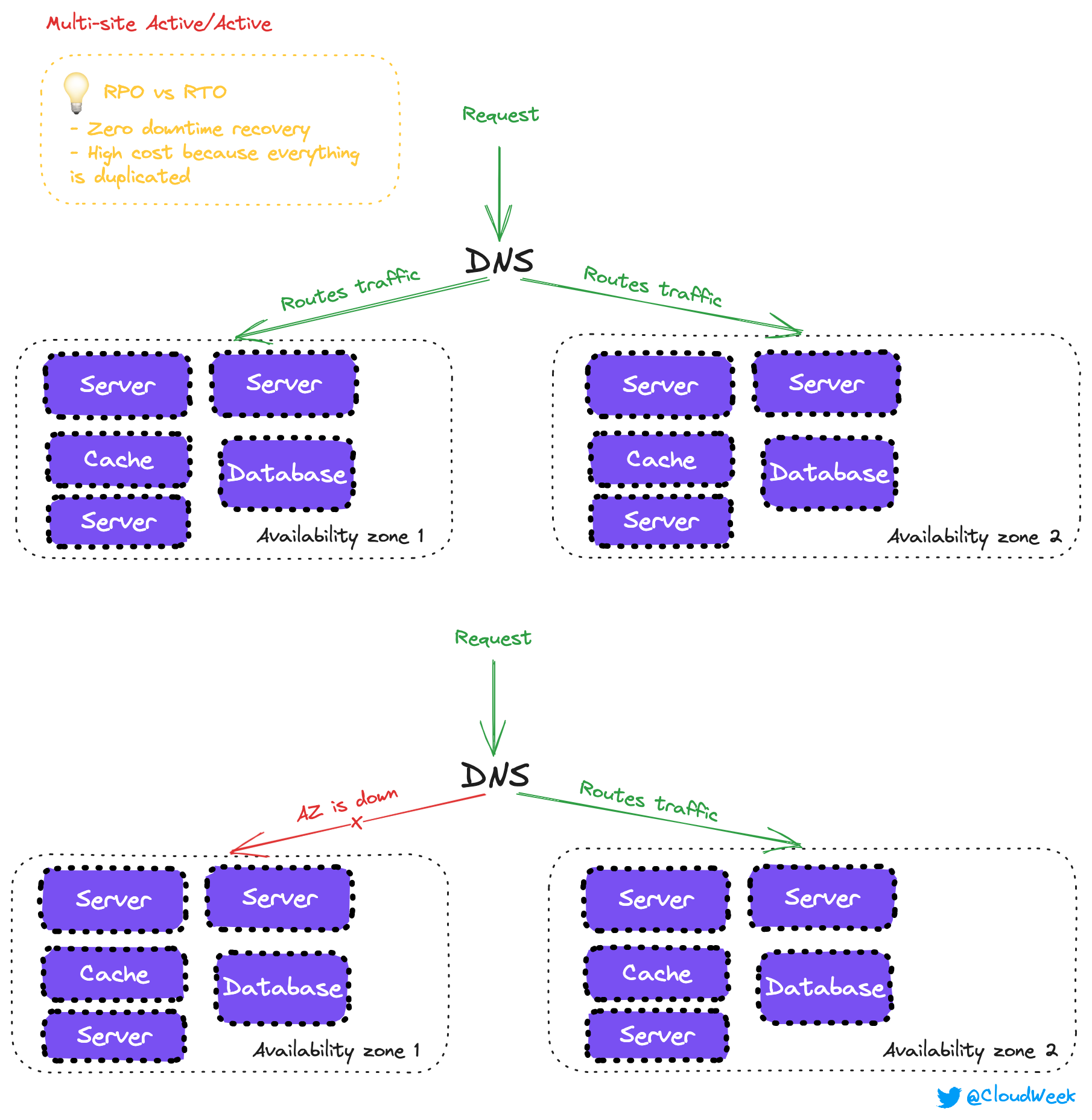
Most of the applications won’t benefit from this type of architecture, and it would be over-engineering for them.
Conclusion
Which one to select? As every senior engineer likes to say, it depends. Business stakeholders can help you drive this decision since they should be aware of what is expected RPO/RTO. Even with your thinking you can choose the appropriate solution since you understand the context in which a particular app is used.
Choose wisely, since using the over-engineered solution for the app which doesn’t bring money into the house isn’t a proper choice most likely. If it brings money into the house, then it probably needs proper disaster recovery.