

Inside Chaos #1: Vitess - How Youtube scaled the MySQL
Inside Chaos #1: Vitess - How Youtube scaled the MySQL
Story about scaling MySQL to accommodate for traffic of Youtube, Slack and many other big companies. Learn about Vitess and how it helped them to shard database.

You might be scratching your head and thinking if this is a lie, and asking: “Youtube and MySQL? MySQL?” Well, it’s true, this is not an ordinary story of scalability, it’s a story of how many big companies are using MySQL at scale. If you still don’t believe me, I get it but read it first. I also write on Twitter daily, at CloudWeek so you can follow me if you want.
Most of us touch on database scalability briefly, we played with DB replicas, partitioning, and shards. But there are challenges with it, and some of these challenges are solved by Vitess.
Well, Youtube built Vitess to handle their load, and many companies adopted this solution later on. So it’s a proven solution. Let’s dive in.
First thing first
Depending on what your app does, there are two problems with the scalability of the Database:
Read scalability
Write scalability
If your application is read intensive, then you need to scale Reads. How do you do it? One of the solutions is to introduce read replicas.
This scaling solution is called Master-Slave replication. Where you have a leader and those that perform work. A leader is responsible to get the writes operations, writing to the DB, and then syncing with the rest of the replicas. And this is a solution you will encounter many times with different services, it’s a common way to solve it. It ensures that writes are consistent since only one of them can write to DB. There are different ways with different DBs, but it’s not a matter of this article, will be covered separately.
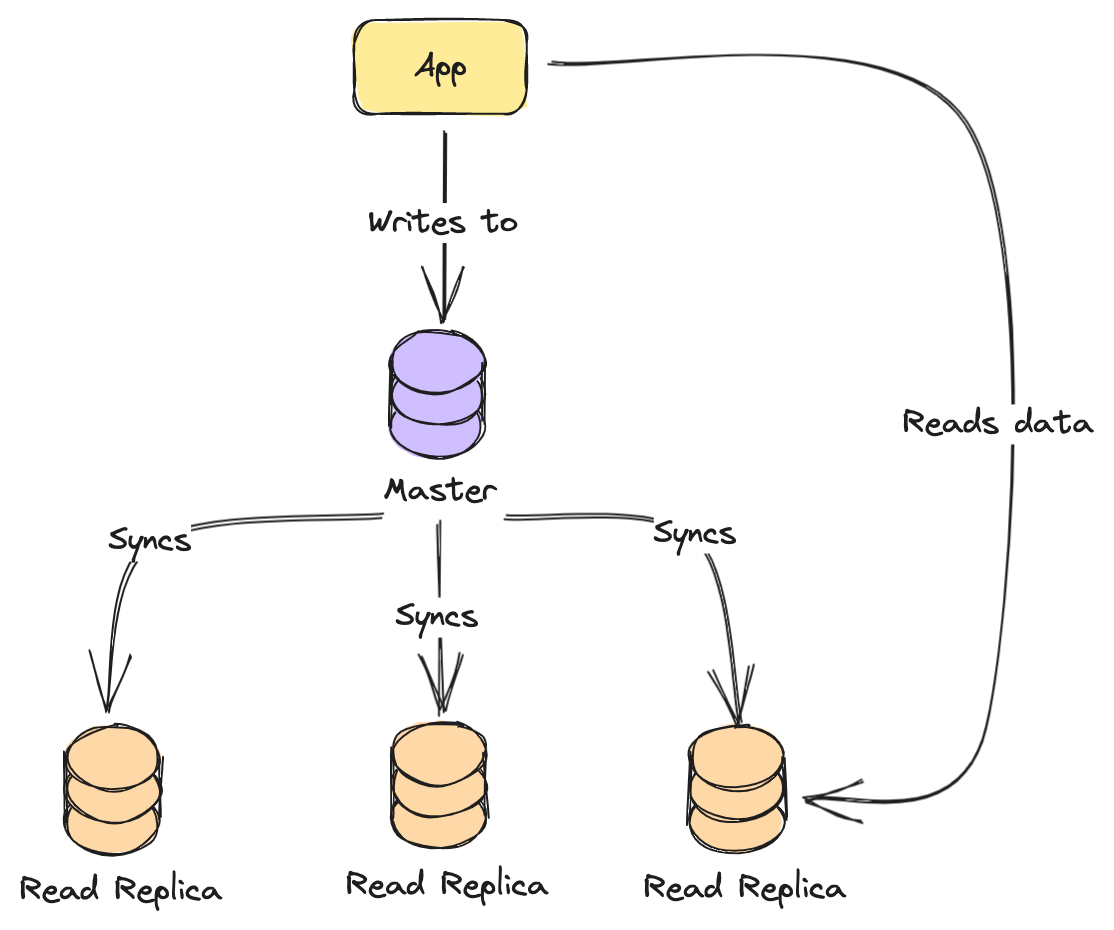
As you can see in the image above, we have one leader, and the rest are Read Replicas. This way, on your reads you have the eventual consistency of a database.
When a write is performed, it replicates data to the rest of the replicas. There is a small delay before data is synced with read replicas, so if you read from them, you might not get the latest result.
This is the first thing that they would do when you try to scale, it’s an easy one and helps to scale Reads. This is what Youtube tried ~15 years ago, of course, it helped for a bit.
What kind of problems are rising from this? The problem is with writes since it’s only performed by one Node. Eventually, your app keeps writing and it throttles your app.
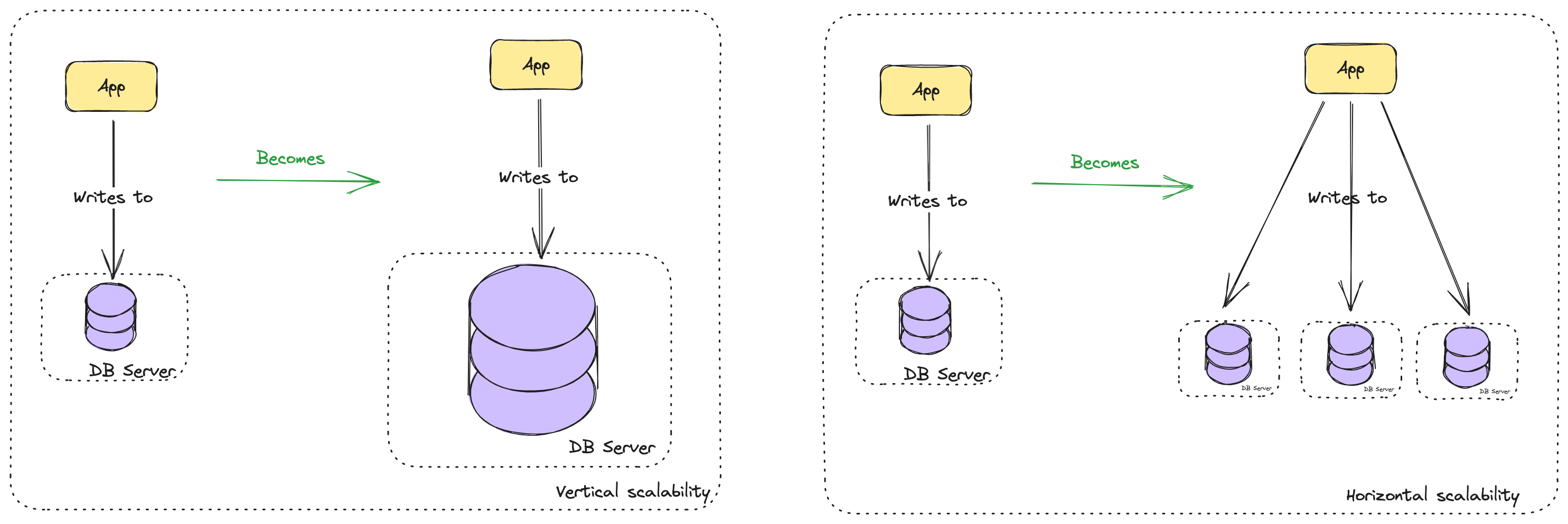
The natural question on this is, how do we scale writes? Either you try to scale your hardware, or you try to shard your database and split it into multiple ones. All databases support this. But if things were not complicated earlier, they just get more complex when your data is split between multiple nodes/servers. Nothing gets easy when your data is distributed.
What is sharding? It’s a way to achieve horizontal scalability with databases. Yes, you can probably do vertical scalability, but it’s a challenge as you grow at that scale. Essentially, with horizontal scalability, you go into multiple servers, while with vertical you scale only one server. So that’s why sharding is horizontal scalability since you are splitting it into multiple databases.
When we know this, we can speak about sharding. In sharding, your database data is split into multiple databases, and you have more than one database now. As I said, if things were not complicated already, they get more complicated now. When you are sharding, you pick based on which data to shard, for example, we can shard based on the ID. But you need to pick the correct sharding, otherwise, your data might not be split evenly.
When data is sharded, all your instances persist in the same schema. You can run the same queries against different shards since all of them are in the same structure.
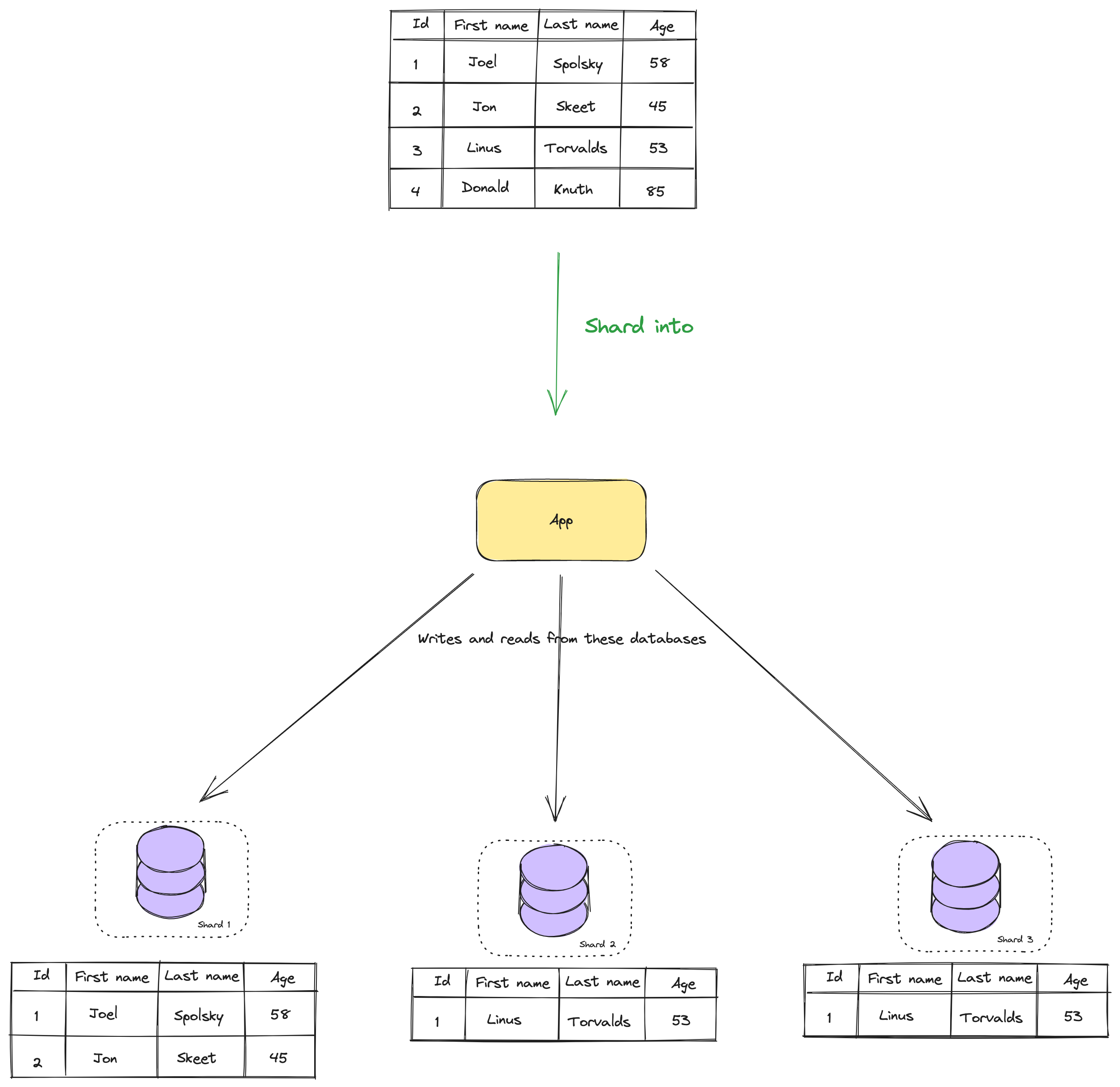
When you shard data like this, and you want to read data, the challenge is in which shard is this data? Either you have something predictable so that you can assume in which shard to look using the hash function, or you store somewhere in key-value pair where that data is, in which shard.
With the key-value store, you need to take care of it and update it. This way, it will work, but you need to take care of aggregation and query of shards. If your data is in multiple shards, you need to query multiple shards and aggregate the data. Plus, sharding has a concept of resharding when data is moved across different instances.
It’s hard to maintain this, even if you are small, but can’t imagine how it looks when you are big as Youtube/Slack/Linkedin, it’s a challenge.
Onward to Vitess
So in 2011, Youtube switched to Vitess, their inhouse built clustering system for MySQL. Let’s look first at high-level architecture and then we can unpack it into what are smaller components part of it.

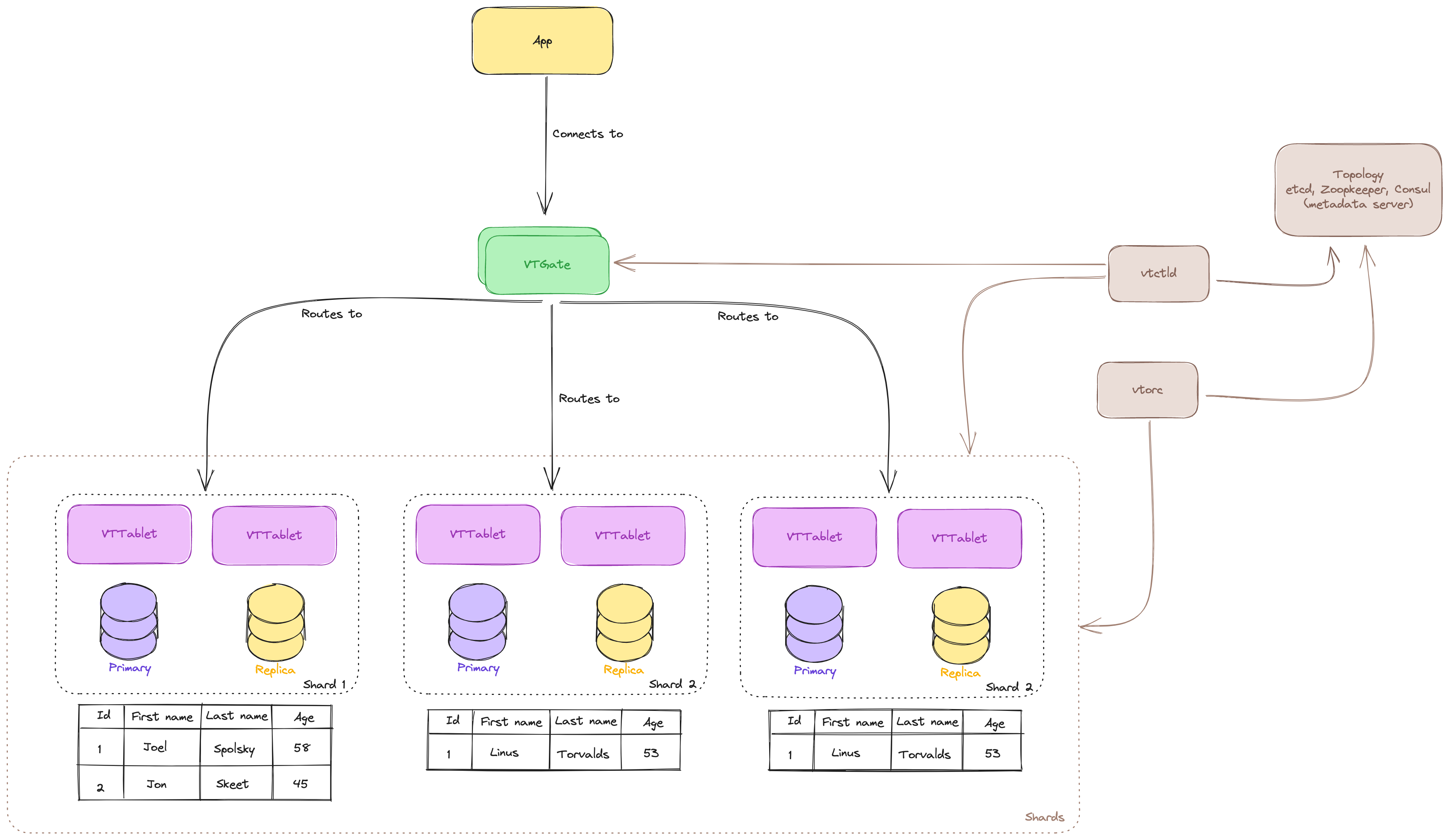
As you can see in the image above, we no longer communicate directly with the shards. The idea is that app doesn’t need to know that database is sharded. After all, all you want to do is read/write data and work with it.
This is where comes up VTGate. VTGate is a proxy server that routes the traffic to the correct shard and VTTablet. With it request is routed to the proper shard, VTGate considers the sharding schema before routing it. You can think of it as some kind of load balancer on steroids for your DB. It evaluates your query and builds the execution plan. VTGate will act as if you are communicating with a single database, and not multiple shards, this complexity is taken care of for you.
But ok, you might be asking what’s the purpose of VTTablet then. It communicates with the local MySQL instance from your shard and has access to mysqld process. By default, it will connect to MySQL over a Unix Socket.
VTTablet is using connection pooling on your MySQL in order to reuse connections. This helps to speed up queries since all of them inside the shard will be using connection pooling by default. And based on the demand, the connection pool will grow to the maximum size you configure. On top of that VTTablet might rewrite your queries in order to make them more efficient.
But there is something wrong with our image above, what if VTTablet fails? What then? Well, it runs multiple VTTablet for a shard, you have a Primary and Replicas. If Primary dies, the replica can be promoted to primary and handle the traffic.

As you can see in the image above, each shard can have its own Primary/Replica instance. This is a failover mechanism in order to have a resilient system. It can also have a read-only instance that can be used for background jobs, like taking backups, and they cannot be promoted to the Primary instance, only Replicas can.
But who stores data about shards and VTTablets? How VTGates understand where to send it? On top of all this, we have Topology Service (TOPO). It runs on multiple servers, store topology data, and provides a locking service. After all, you need to share some data between shards and discover them.
Topology exists to:
Enable VTTablet to coordinate and act as a cluster
Discover VTTablets in order to enable routing from the VTGate
Stores configuration
This part of the system is a plugin system, by default, it will be using etcd to store data, and if you don’t know what is etcd, it is a key-value store. But since it’s built as a plugin system, you can switch to something like Zookeeper or Consul.
Topology is not used all the time when VTGate needs to route the query, it would cache data on VTGate. But, when a node is started, it would get data about the node and store it, and it gets updated as the node changes.
As you can see in the image above, it evolved even more. Now we have Topology which stores data about our Vitess.
But we have two more components:
vtctld - together with Topoligy is responsible for managing the data: recording metadata, shards,…
vtorc - it gathers data about MySQL instances from VTTablets and instructs to fix them in case it thinks they are failing. Of course, it communicates with Topology to understand what is the state of topology and based on that makes decisions. This can help you build monitoring on top of Vitess for your Shards and MySQL.
Nothing comes for free, and every architecture has some tradeoffs. When you scale your application with Vitess, you cannot expect to have the same consistency as you would have with one MySQL server. I think that’s kinda obvious since in distributed systems it’s rather hard to guarantee it. Some things have to be sacrificed for this type of scale.
When you are reading from the replicas, there could be delays in replication which cause you to see old records. With Vitess, if you want you can request to read from the primary instance, but in my opinion, you should avoid it unless it’s absolutely necessary since you will have higher scalability with replicas.
There will be also some latency because VTGate will be taking care of routing, but I think it’s justified since it helps you remove complexity from the app.
Multi-AZ and Vitess Cell
But you are Youtube, and of course, you need Multi-Region/Multi Data Centers deployment. In Vitess this is done using something that is called Cell.
A Cell is a group whose failure is isolated from the rest. It can be a group of servers, a data center, or in AWS terms region/availability zone. When you have things separated like this, you will be more resilient, but costs will go up. After all, if you use this type of architecture with Vitess, you probably have big bags of money, so you might not care about costs.
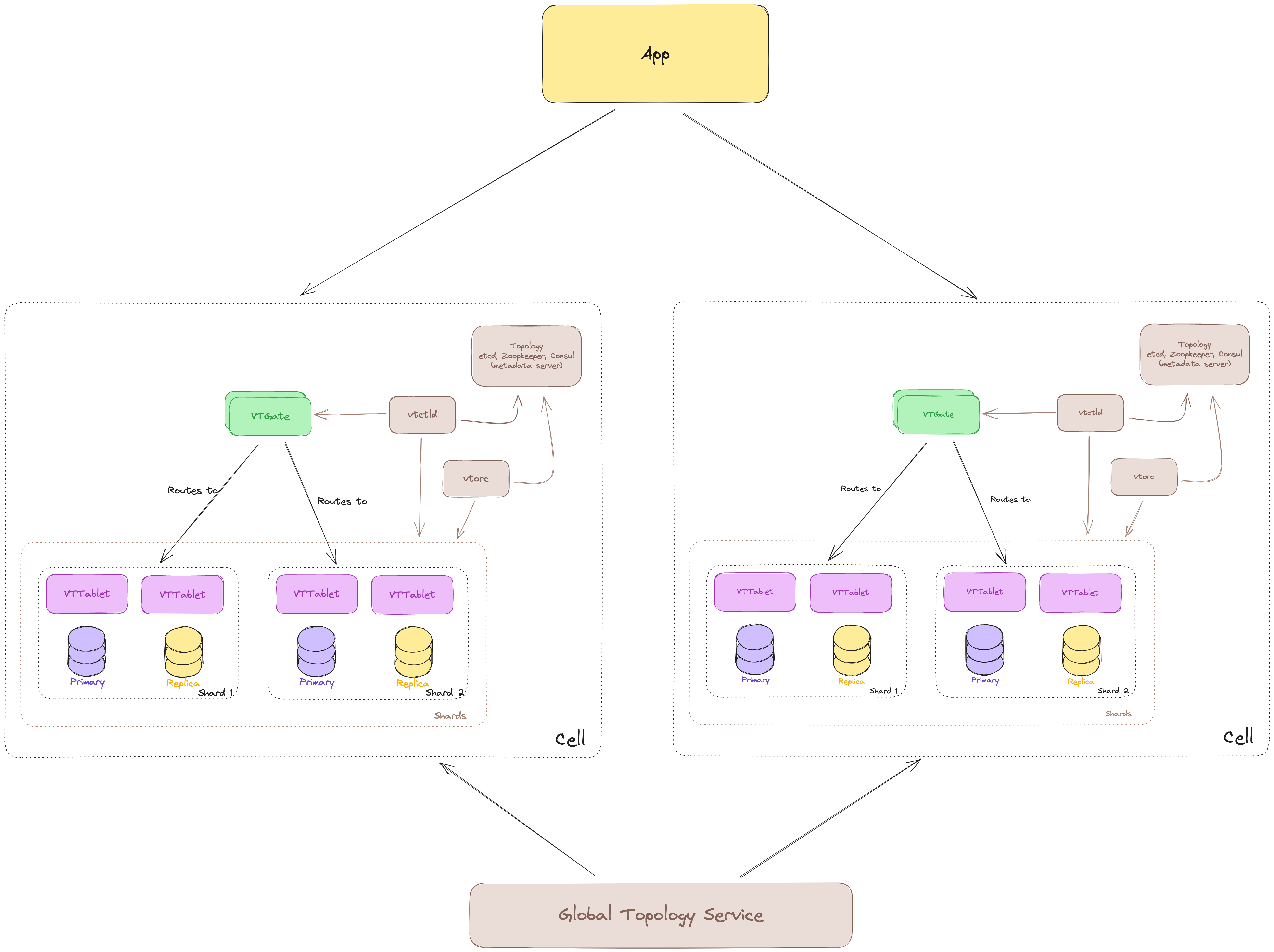
You can see that now cells are separate. Each cell is a story for itself and has its own Local Topology Service, vtctld, vtorc, etc…
While at the top, you have Global Topology Service which stores metadata and shard information at the global level. It’s also advised to scale Global Topology Service across multiple cells in order to make it resilient to single failures. This way your cluster can continue to work in case of zonal failures.
Conclusion
More and more I think that solution is divide and conquer. When your app gets this big, you are processing a huge amount of TPS (Transactions per second), and it gets easier when things are smaller. I love that this solution builds on different ideas, it can remind us that we can always build on the shoulders of the giants.
As you are getting to the higher levels of scalability, it’s always a good thing to look at neighbor yards and see what they are doing. Youtube is the one that started doing this first, but a lot of the big companies followed and used Vitess.
We will be getting more into the details about Vitess and deploying it to EKS on AWS in some of the future posts, so subscribe to get it.