

AI and Serverless: The Good, the Bad, and the Ugly
AI and Serverless: The Good, the Bad, and the Ugly
How do you train and use ML/AI models on Lambdas? Should you even do it?

This is a story about how the wrong direction when designing the app can cause you a headache. Nobody designs anything perfectly on the first try, and I'm guilty of this too.
We finished our experimentation phase. There was a plan for what machine learning models are we going to use and how are we going to train them. The time has come to start talking about engineering and to see how are we going to deploy the system. There were restrictions from the DevOps team, so we settled on using some existing infrastructure. The AWS Lambdas.
What could possibly go wrong, right?
Happy that we managed to train some models that actually work, we went on to the coding phase. Wrapping everything up in a FastAPI API, setting up a DB, and deploying the initial version. The system was divided into two services. One is to handle the data management and the communication with the rest of the system. And the other to do the AI/ML stuff. Both were deployed on the Lambda infrastructure. The communication was implemented using Lambda async calls. No queue for the initial version :(

We were solving an issue of text and token classification in the legal tech domain. There are a bunch of contracts and people want to find specific things and it's time-consuming. As lawyers are expensive it was worth speeding up the whole process.
To solve the problem we used small sentence transformer models and contrastive learning. The model was only a couple of hundred MBs and fast enough to run on a CPU. In contrastive learning you provide both negative and positive samples to the model, group them in pairs and the model learns to push them apart in its embedding space. To cover it more in-depth, we would have to dedicate a whole post to it.
The more curious can read the blog post that explains it in more detail. What is important is that this technique is good when you don't have a lot of data. But the training will take more time.
A great image from v7labs that showcases contrastive learning:
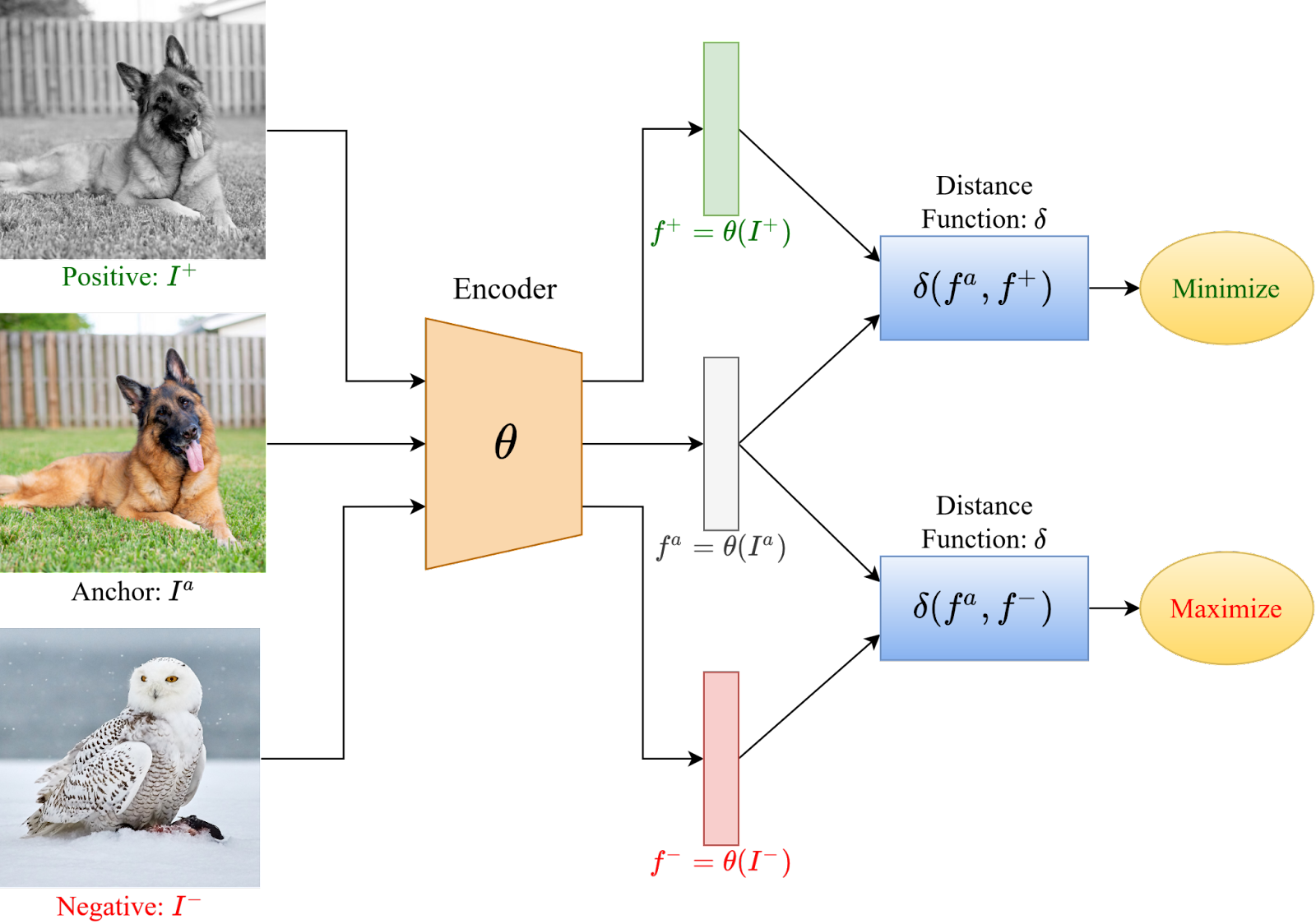
Once we started testing with real examples the issues began to surface...
With bigger paragraphs, we got OOM (out of memory) errors. Our first idea was to increase the instance memory, that's easy, right? The largest instance has 10GB of RAM. The errors were still happening from time to time.
We can decrease the batch size (the number of examples that are passed to the model at once). Good, that solves it. We want the users to provide us with as much good data as possible. So we test what happens when we add even more data. No response from the API.
The job stays in the status "running". But it was working locally. Let's try again. Nothing. Check the logs. The model is loaded, data is passed correctly, and the training is progressing. And then it stops. No more logs. What's happening?

And then it hits us, pretty obvious, the lambda times out... A lambda may be active for a max of 15 mins, then it just dies. That may seem like more than enough for most traditional web uses cases, but in ML it easily becomes a problem. Especially when you're only using a CPU. Even more, if it's a weak CPU.
This is something that should have been more thoroughly discussed in the design phase. As the saying goes, if it can happen, the users will find the way. You shouldn't force any solution only because of organizational issues in the company.
How can we fix it?
The inference part (when you use a trained model to give you the predictions) was doing okay. That can stay on lambdas.
The training needs a different approach. We need something that can run longer, even better if it has a GPU.
All hail to the EC2 instances. They are basically virtual servers that AWS provides. And they are configurable. You can pick the CPU and the RAM memory size, and use a GPU. Everything that we need. There are multiple ways to make it scalable. We choose to create an ECS group.
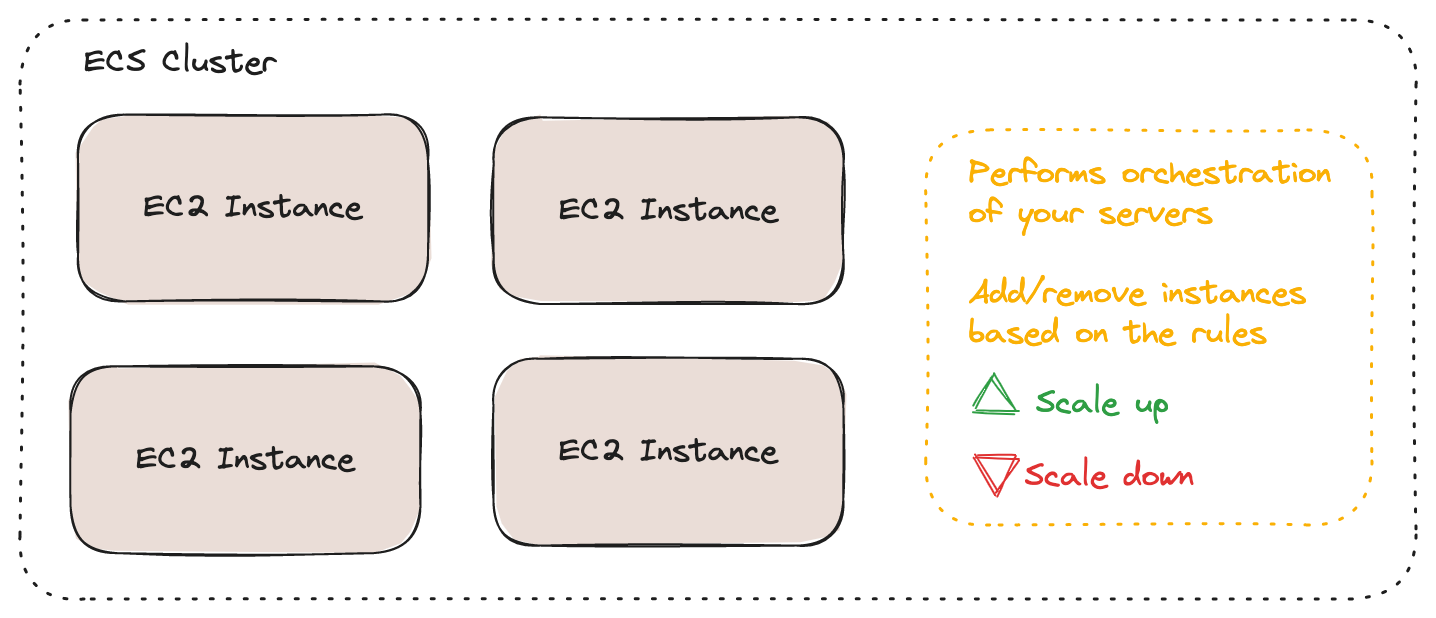
ECS is a logical grouping of EC2 instances and it allows autoscaling. We can set up the min and max number of instances. For a better understanding of autoscaling, you can read our previous post, DevOps Concepts #2: Autoscaling
We need a way to communicate between the services. Using a queue is a good practice, we choose SQS. If you are wondering why SQS, you can read more about it here: Building Fault Tolerant Systems on AWS.
Because we don't want to download the models from S3 every time we want to use them, we appended an EFS to our cluster. You can think of EFS as an elastic/configurable hard disk that can be mounted to instances.
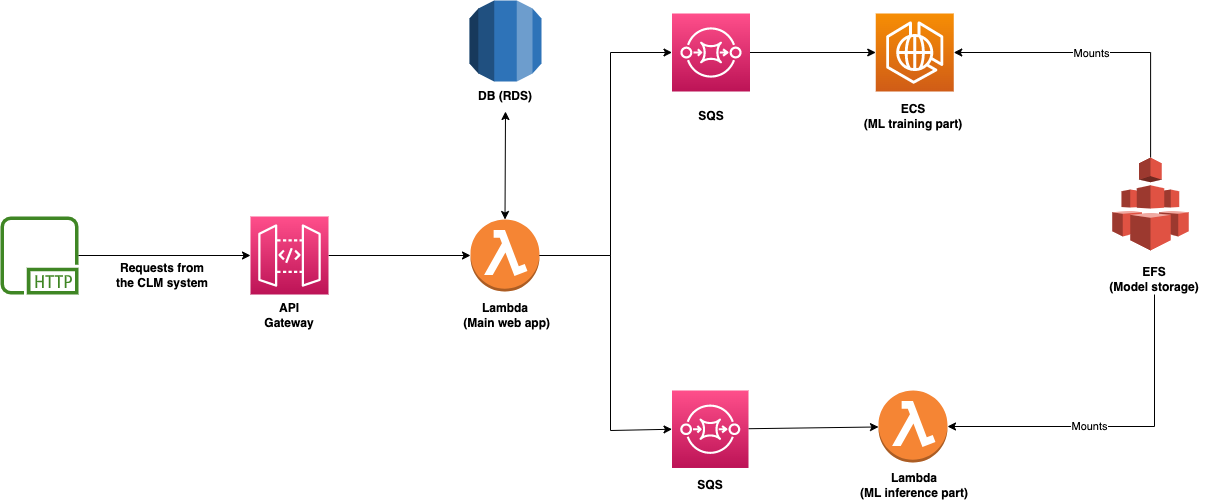
To sum it up, the components that we use:
ECS - main computing horsepower. Used for heavier and time-consuming jobs of training models.
EFS - storage for models and documents. Everything that needs quick access.
SQS - queue used for the communication between services
Lambda - runs the less resource-sensitive tasks. CRUD operations, orchestration of requests, and running the existing models on documents. In some cases, the inference part must also run on GPU machines.
Main takeaways
If the thought "Can this run on a Lambda?" even crosses your mind, don't use them. Things can likely get more complicated than you can anticipate. This is especially true if you are tackling ML/AI problems.
That being said, the serverless infrastructure is a mighty tool. You just have to know when to use it. In the context of ML, if you want to train and deploy a deep learning-based model, it's better to skip it. For more traditional algorithms, that are small and really fast, it can be a good fit. But always take into account what (pre)processing needs to be done, how are you going to train the models, how many predictions are you going to have, etc.
Wrong design decisions can be costly since you go in the wrong direction, and this affects the architecture, and changing the architecture takes time. This is our first post that covers the intersection between AI and Cloud technologies. We'll talk more about how to design and deploy those systems. What other technologies we can use. (Has anyone used/heard of Sagemaker?)
And in general, what are some problems that we can face.