

AI Architecture #1: Unleashing the Scalability with SageMaker
AI Architecture #1: Unleashing the Scalability with SageMaker
🤖 What is a ML system? Why do you need it? How to create it?

In one of our previous posts we discussed the issues we faced in using AWS Lambdas for AI/ML. Today we’ll dive into an AWS service specialized for training and deploying AI models. SageMaker. Even the name sounds smart.
What are ML systems and why do we need them?
The business stakeholders decide there is a problem that can be solved using ML/AI. Some data is gathered, and a model is trained. It’s tested on a couple of examples. It works! And we are done.
Not exactly…
Even if the business case was properly laid out on the first try. And it never is. Even if there are numerous labeled examples ready. And there never are. Even if the first model works great. And it usually doesn’t. We still don’t have a reliable system.
The models can’t be static. We need to train them on new data. There should be a mechanism to collect user feedback and leverage it in the training. We need to monitor the model performance. Code, data and models need to be versioned and stored. We should have a CI/CD pipeline. The training code shouldn’t be run manually on local machines. And so on. Basically, we need a system.
There are a lot of tools and libraries that we can use. Both open and closed source. Today we’re going to examine how SageMaker can help us with the problems I’ve mentioned.
SageMaker has two main tasks:
model training and
model deployment.
We’ll cover both and analyze how you can create a whole system architecture around it.
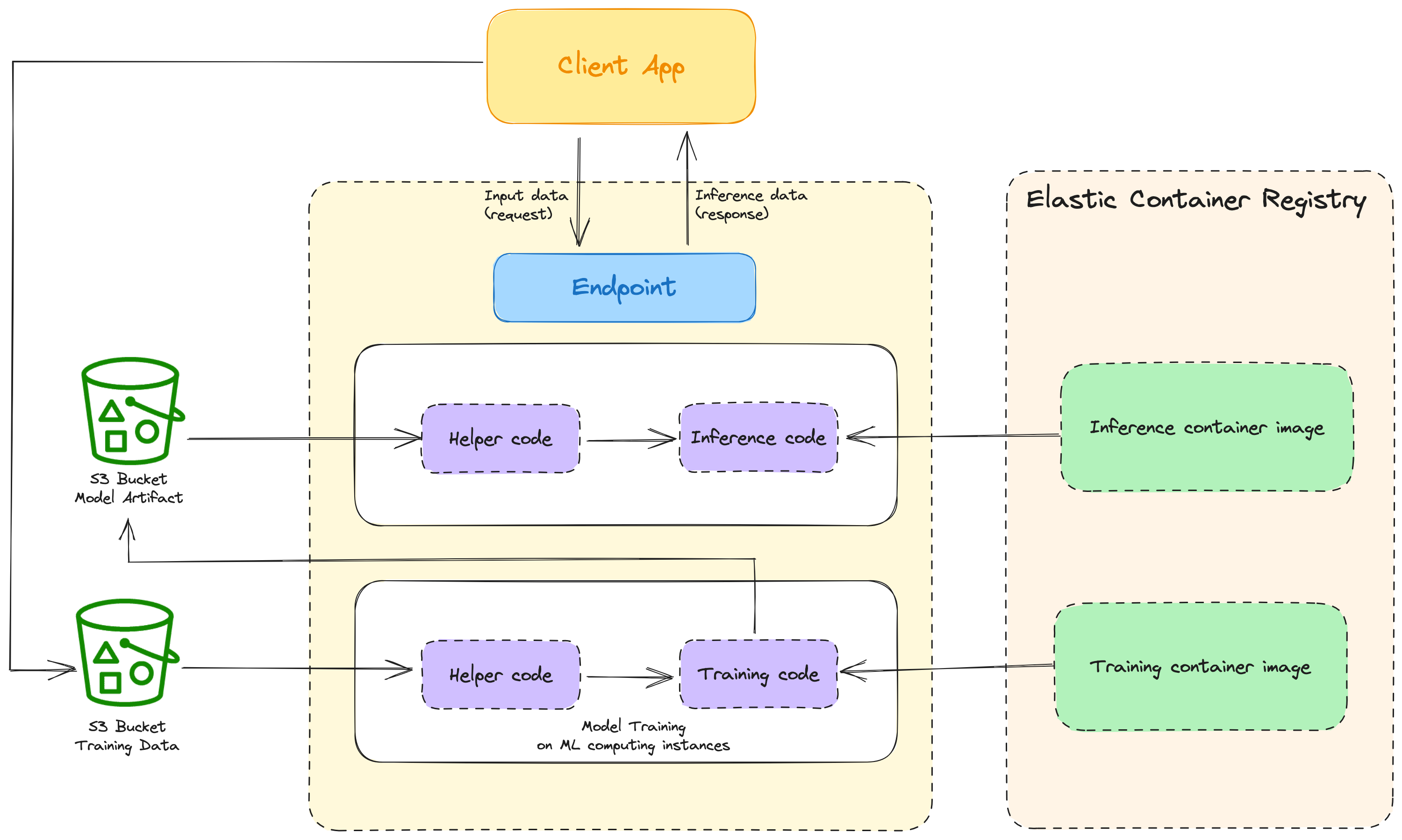
Training
First thing first, we need to train the models. To make it a repeatable process, that can be executed time after time, we need a training job. It will help us automate the training of our models. Enabling us to constantly adapt to new data. Remember, the models learn from data.
The training job needs the following things:
URL of the S3 bucket that stores the training data
Compute resources that will be used for model training
ECR (Elastic Container Registry) path to the Docker image containing the training code
URL of the S3 bucket that stores the output of the job
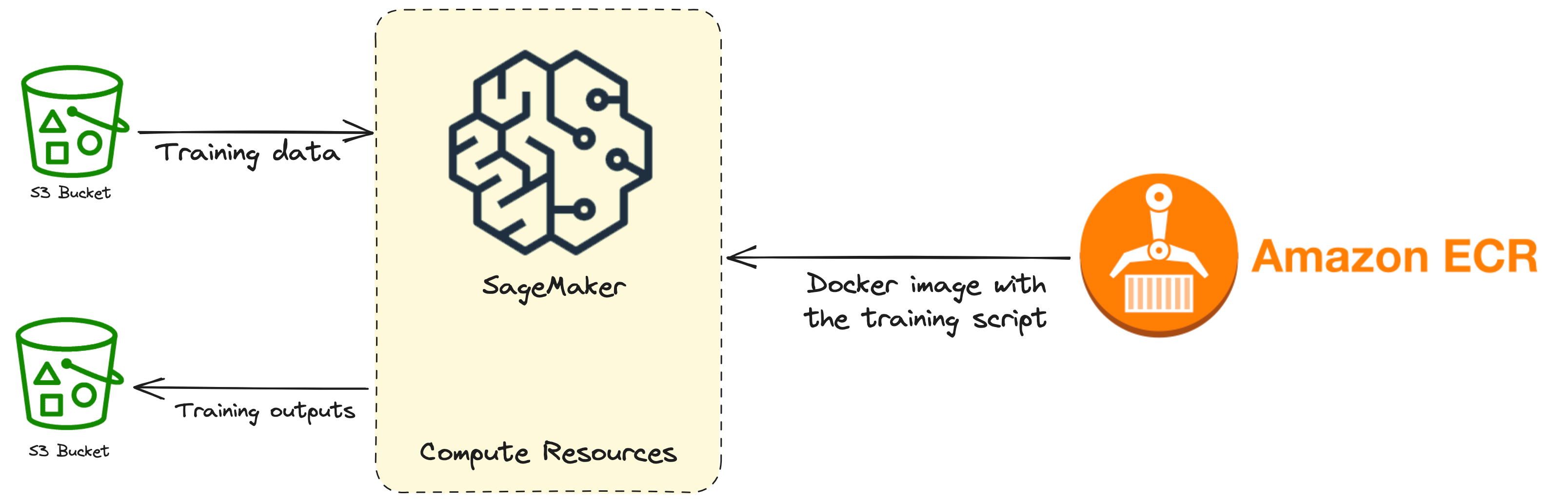
The S3 part is pretty straightforward. The inputs (training data) and outputs (trained model) of the training will be stored using S3. Another option is to use EFS or FSx. If there is a need to pass some other training configuration, we can do that through arguments.
There are a bunch of different instances that can be used. We’ll use ml.g4dn.2xlarge. It has a T4 GPU, 8-core CPU, and 32 GB of RAM. That should be enough. T4 isn’t a particularly fast GPU, but it has enough memory and will do for most use cases. If you’re doing some really hardcore training, there are also some monster machines to accommodate you. A list of all instance types can be found on this link.
SageMaker heavily relies on Docker containers. To train a model we need to write the code that will do the training. That code needs to be encapsulated in a Docker image and passed to SageMaker (using ECR). We can either use existing Docker images that SageMaker provides, extend them or create our custom ones. Their images support most of the popular ML frameworks (PyTorch, HuggingFace, ScikitLearn, etc.) and are good building blocks for most problems we can encounter. You should first check if their pre-trained models and built-in training algorithms cover your needs.
Inference
To explain the ML lingo, inference means using a trained model to get (infer) results from data. Are you still confused? Imagine you have a model that is trained to detect spam. That is a hot topic on Twitter right now. Using that model on new DMs, to classify them as spam or not is an example of inference. To sum it up, the usage of the trained model is inference.

There are multiple ways you can deploy models and run inference on SageMaker. There are 4 different inference options:
Real-time inference
Serverless inference
Async inference
Batch transform
Let’s explain them in more detail.
Real-time inference can process payloads with the size up to 6MB and the maximum inference time is 60 seconds. The payload size can limit us in what problems we can solve. For instance video or audio files would be quite problematic, even images. With 60 seconds we should only run the inference on smaller inputs. (Ex. run the prediction on a couple of paragraphs, not the whole document)
Serverless deployment has similar constraints to Lambdas. Max ram size is only 6 GB. That’s not enough to reliably run the state of the art deep learning models. You don’t always need them, but we should keep the constraint in mind. We should use this option only with really small models and data inputs.
Batch transform is suitable for offline inference on batches of data. We use this to get results from large datasets and when we don’t need a persistent endpoint.
Async inference, as the name suggests, queues the incoming requests and processes them asynchronously. With the payload size up to 1GB, most tasks won’t be a problem. We can also scale the instances down and only pay when our endpoints are processing something.
But how can we use this?
There are a lot of options and it can feel overwhelming. Where to start? What do we need? Let’s take a look at what is the fastest way to expose a model to the rest of the system.
First we need to train the model. To do that we need a notebook instance. You can think of a notebook instance like a virtual machine that will run all the code.
Under the hood SageMaker uses EC2 instances. In the instance tab you can see the machine type that we selected.

Once that is set we start the machine and open the JupyterLab (or Jupyter). Jupyter is a web-based interactive computing platform. You can write code into cells, run it and see the outputs beneath the cell.
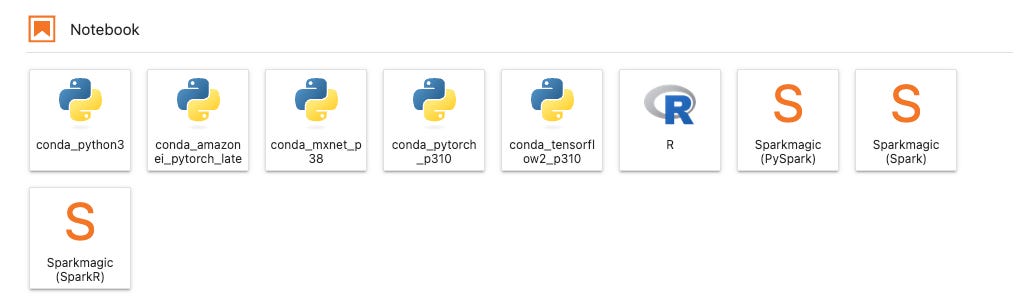
Next we select our kernel and create a notebook. We’re talking about a file in Jupyter, not a VM we mentioned earlier. The kernel specifies the language version and the major libraries. (ex. PyTorch 1.10 Python 3.8 CPU Optimized).
Example of different kernels:
In the notebook we write the code that is used for training, like we would do in any other editor. We’ll need to load the data, pick a model and train it. In this example we’ll use the HuggingFaces library. It’s the de facto standard for all modern NLP approaches.
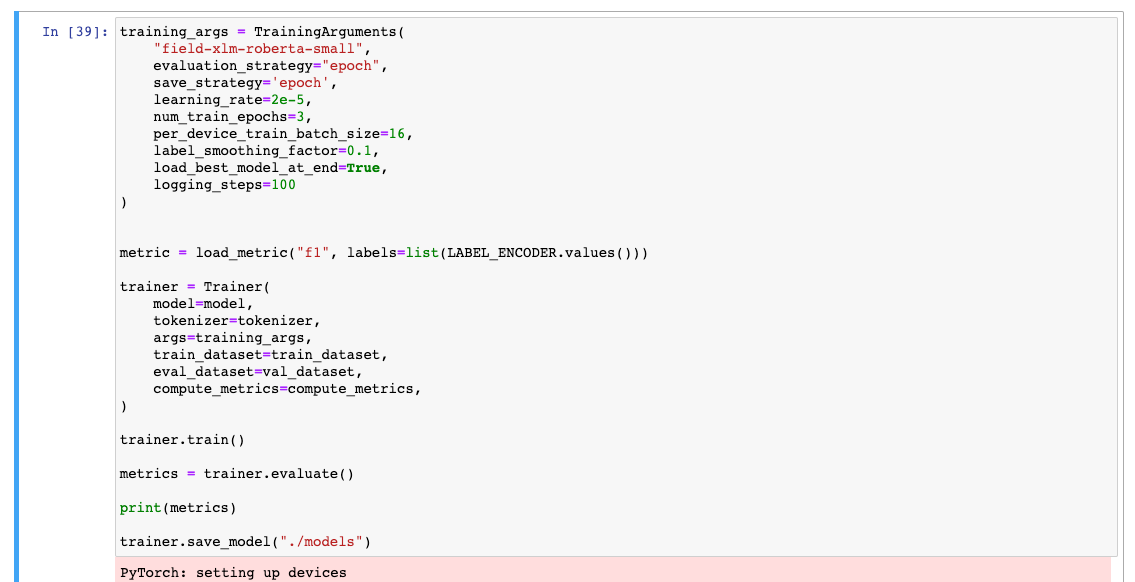
Once we train a model, we need to upload it somewhere. We’ll use the S3 for that. After that we are ready to deploy the model to a SageMaker inference endpoint. To do that we use the HuggingFaceModel wrapper from the sagemaker library. We’ll also need to provide the model location (S3 path), IAM role and dependency versions (or a path to the Docker image). After that we just call the `deploy` method and specify the number of machines and their type. The code that does all this can be seen below:

We can call the predictor from our code and test if it works. This is the output of a simple question answering model:

To get the model endpoint, we can access the endpoint_name field. This will be useful later on, once we start to connect the whole system.

Okay, we have a model and it’s deployed.
But now what?
The simplest way to expose the model to the rest of the system is through a REST API. To do that we need to define an API Gateway.

To use the API Gateway to create a REST API that will connect to the SageMaker backend we need to define a couple of things:
Method request - HTTP request definition (methods and body/params)
Integration request - how the REST request maps to the format expected by the backend service endpoint (in our case SageMaker inference endpoint)
Integration response - similar to the integration request, but for the response from our endpoint.
Method response - HTTP response definition
Since we don’t have a Lambda proxy between the API Gateway and SageMaker endpoints, we’ll need a mapping template. The mapping templates are defined using Apache Velocity Template Language (VTL). It can be used to convert from one JSON format to another.
In this case from the REST request format to the model input format, and from the model output to the REST response format. We can see an example on the image bellow:
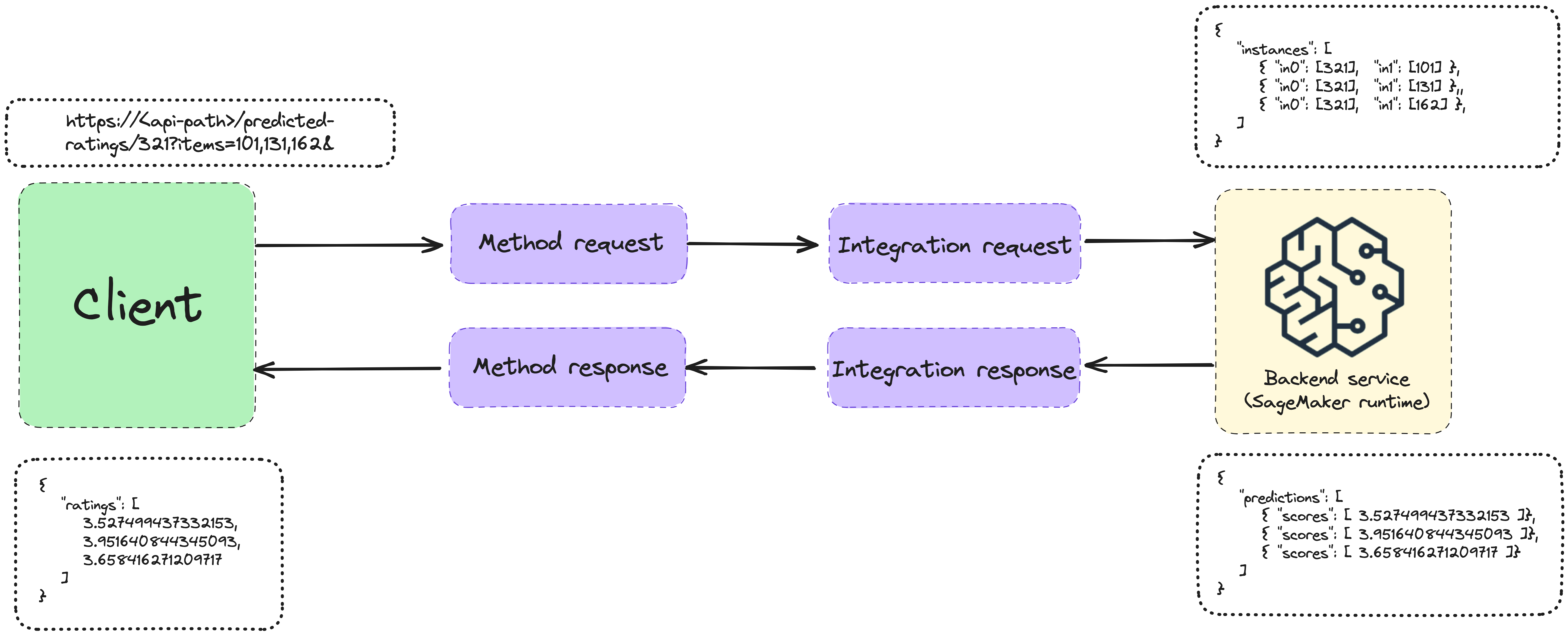
When we create the methods in the API Gateway we have to specify the integration type. In this case, it’s the AWS Service and then we can select the SageMaker Runtime.
Voila, we can now test our first endpoint!
A more complex architecture
In the next article, we’ll cover and explain a more sophisticated architecture, that builds on top of SageMaker.
I’ll give you a sneak peak:
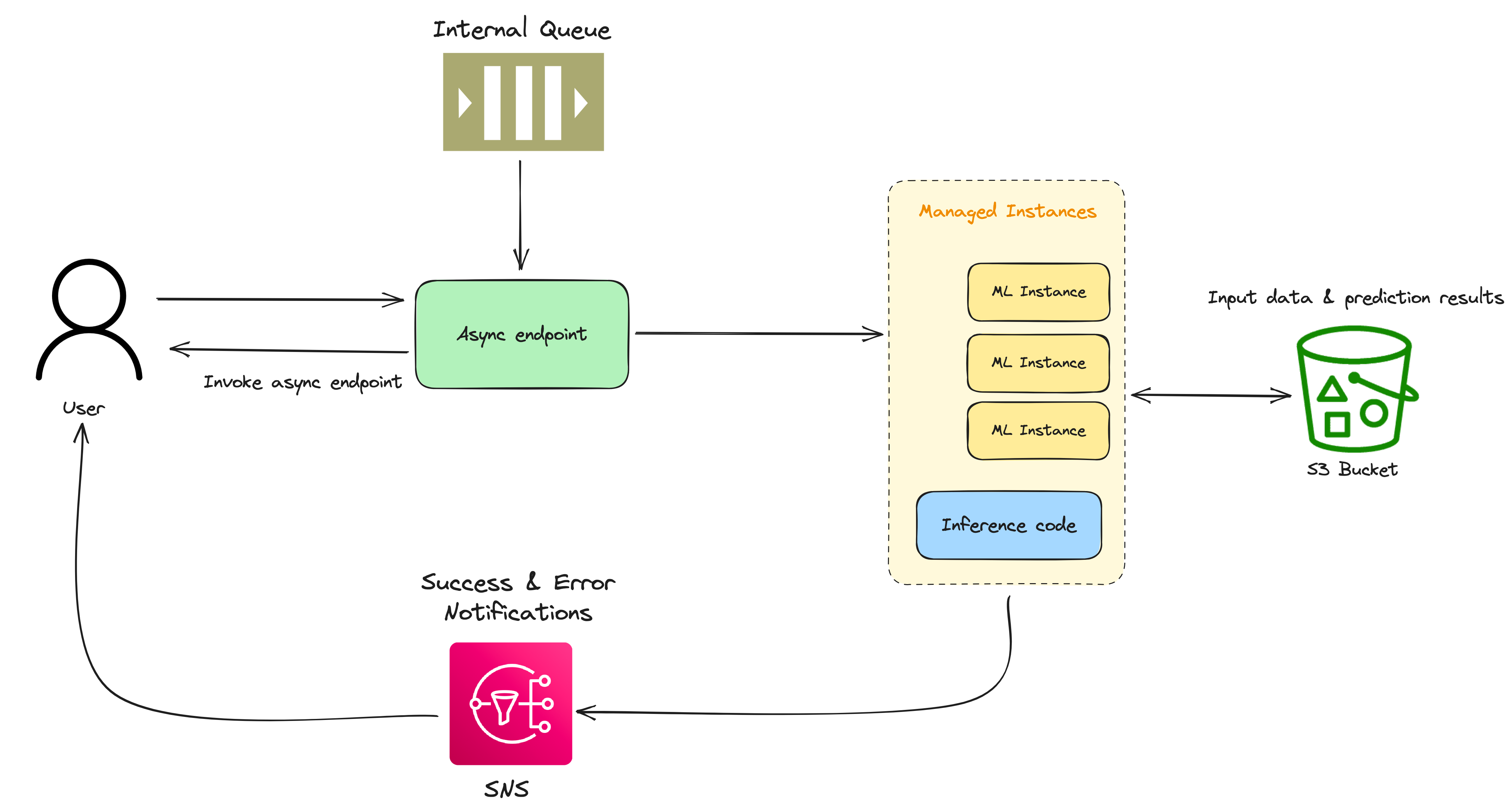
Conclusion
We are only scratching the surface here. SageMaker is a powerful and versatile tool that can be used to solve a lot of different problems.
However, it does add an additional premium over the AWS infrastructure. If you’re ready for the additional cost and vendor lock-in, it can be a mighty weapon in your arsenal.
Let us know how you like this format, where we are more hands-on. We read all the replies!